Polblogs
Polblogs[1] is a network of 1,490 nodes for websites of political blogs on the 2004 US president election and 19,025 directed links by citations from citing blogs to cited blogs. Each blog site is classified by the blogger's self-claim as either republican or democrat. The largest weakly connected~(LWC) component has 1,224 blog sites, 158 of which make no citations to others (zero out-degrees), 233 nodes receive no citations (zero in-degrees). Among the 266 nodes outside of the LWC subnetwork, only two sites are linked, the rest are singletons.

|

|
Largest weakly connected subnetwork $G$ of Polblogs in a spatial embedding in (a), its adjacency matrix in (b). The democrat cluster is in blue, the republican cluster is in red by the ground-truth labels. Each cluster is weakly connected but not irreducible: each diagonal block has leading zero columns (associated with the blog sites without outgoing citation links) and tailing zero rows (without incoming links).
MNIST
MNIST[2] handwritten-digit image dataset. It contains 70,000 gray images of handwritten digits (0 to 9), each is a $28\times 28$ pixel array. This dataset is used extensively for benchmarking supervised, semi-supervised classification algorithm or unsupervised clustering since the work by Yann LeCun et al.[2]. We construct $k$-nearest-neighbor~(kNN) graphs ($k = 25$) of the image data by the Euclidean distance between the HOG image feature descriptors of length 144.[3]

|

|
The kNN graph $G$ (k = 25) of MNIST of 70,000 handwritten-digit images in a spatial embedding in (a), its adjacency matrix in (b). The contents of the 10 clusters are shown by miniature digit images on sampled points in the spatial embedding of graph $G$.
CITE75_99
CITE75_99 is the patent citation graph described initially by Hall, Jaffe and Trajtenberg (HJT) in 2001[4]. The data files are available at the NBER public use data archive. The graph represents 3,774,768 U.S. patents registered between 1963 and 1999 and 16,518,948 recorded citations between 1975 and 1999. The largest weakly connected (LWC) component contains 3,764,117 (99.7%) patents and 16,511,741 (99.9%) recorded citations. We refer to this LWC component simply as CITE75_99.
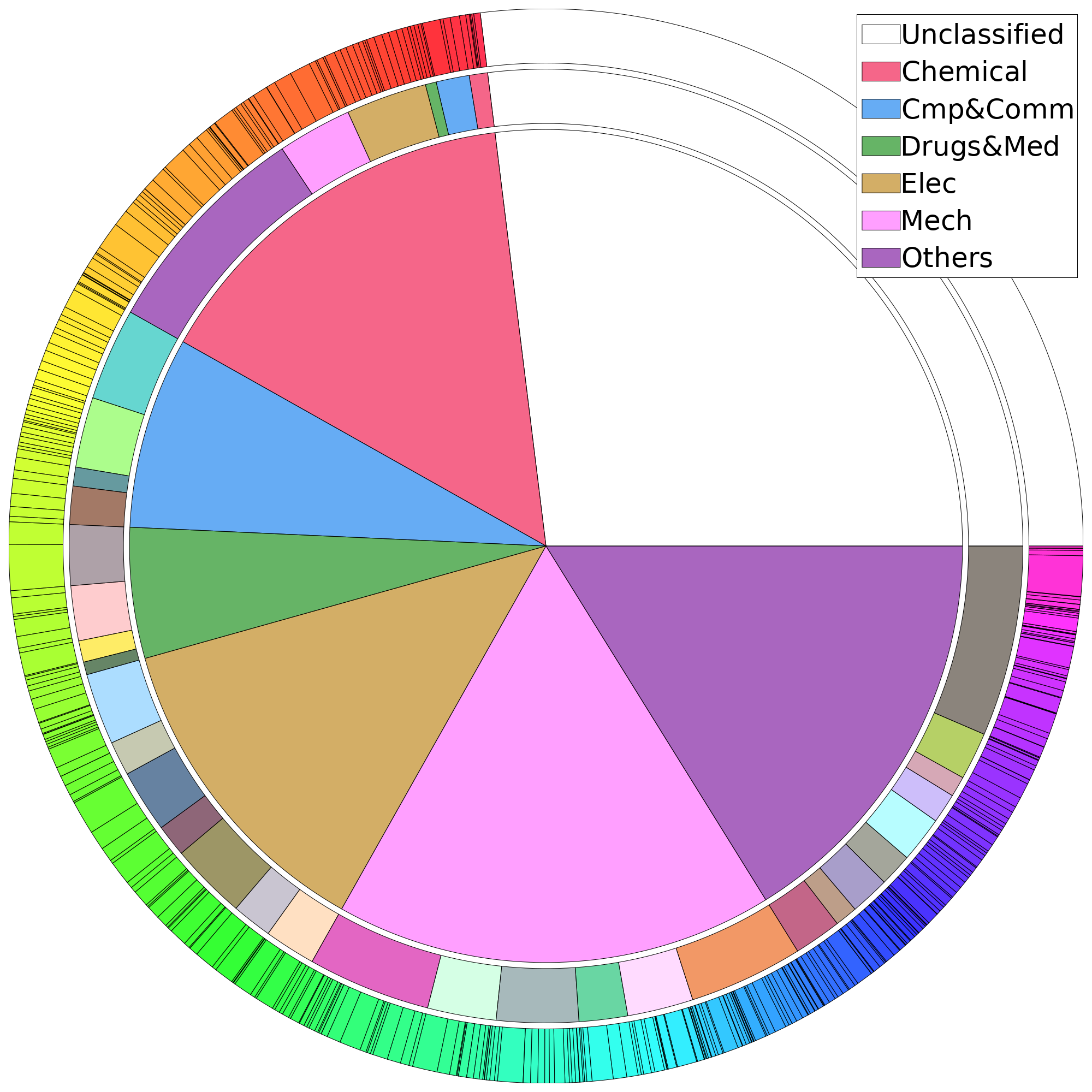
About 74% of the patents CITE75_99, 2,755,865 precisely, are attributed with a 3-digit code index each according to the USPTO patent classification system with $418$ technological code indices as of 1999. Each code index is associated with a list of technological terms. The rest, more than $1$ million U.S. patents, have no electronic records of classification information or semantic annotation.
HJT give two additional meta-category codes to every patent with a USPTO code. The first meta-category system has $6$ broad categories, (1) chemical, (2) computers and communications, (3) drugs and medical, (4) electrical and electronics, (5) mechanical, and (6) the others. The last category is the complementary of the previous five. The second meta-category system has $36$ finer partitioned categories. It is a non-overlapping aggregation of the $418$ class codes and it is further aggregated into the first mega categories.
|

|

|
|

|

|
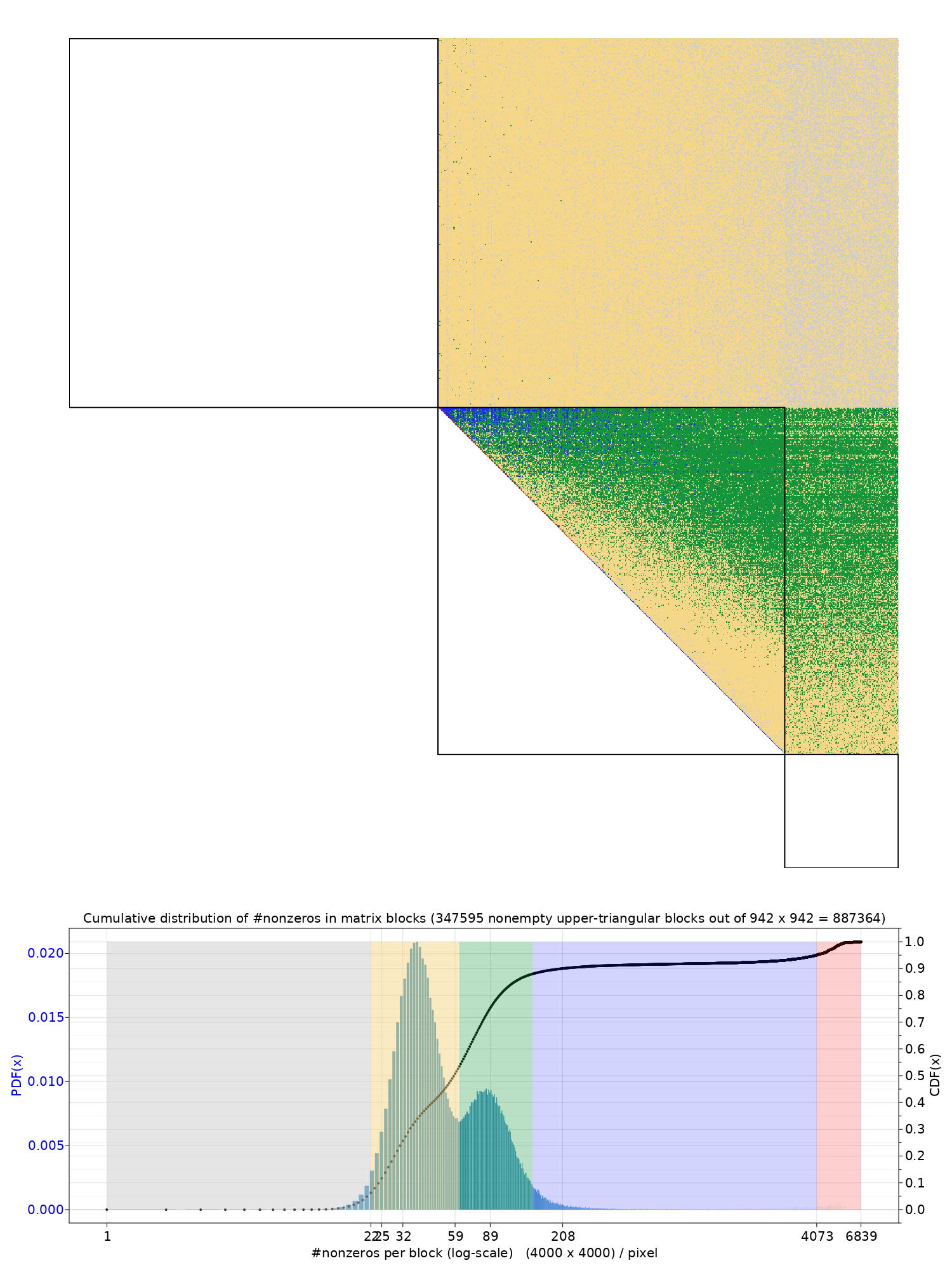
Block-wise images of the adjacency matrix $A$ of CITE75_99 in three different vertex orderings, (a), (b) and (c). Each pixel on the matrix image represents a $4000 \times 4000$ matrix block. Below each matrix image is a histogram of citation edge density across matrix blocks. The black curves in the histograms are the cumulative citation count. Every pixel is color-coded by the number of citation edges in its underlying matrix block, in matching colors to the distinctive areas in the corresponding histogram. (a) The vertices are in the HJT ordering as in the data files provided by HJT and colleagues. (b) The vertices are in the ordering obtained by the Dulmage-Mendelsohn (DM) permutation, which is preceded by a random shuffling. Remark b-1: This ordering uncovers a typical ternary structure of citation graphs, or digraphs in general, due to isolation or truncation of external connections. The first block on the diagonal is defined on $V_{\rm sink}$, the sink vertices without outgoing edges (zero out-degrees). The last block on the diagonal is defined on $V_{\rm source}$, the source vertices without incoming edges (zero in-degrees). The middle represents one or more than one weakly connected subsystems of the vertices that have both incoming and outgoing edges. Specific to CITE75_99, there is one weakly connected subsystem in the middle; the sink vertices follow the initially randomized ordering, so do the source vertices. Remark b-2: This ordering (b) also brings highly connected patents closer, as shown by the histograms where there are matrix blocks with substantially higher edge density, by orders of magnitude, in comparison to that by ordering (a). (c-1) & (c-2) The vertices are in the DM++ ordering. The sink vertices are ordered by the DM permutation on $A( V_{\rm sink}, V )$, i,e,, by the connections between all sink vertices and the rest. The source vertices are similarly ordered by the DM permutation on $A( V, V_{\rm source} )$. More latent structures are revealed, see the three heavy/dense traces that indicate strong temporal-thematic connections among the patents on the traces, in additional to the strong connection on and near the diagonal. These traces are highlighted in (c-2).
References
- 1L. A. Adamic and N. Glance, “The political blogosphere and the 2004 U.S. election: Divided they blog,” in Proceedings of the 3rd International Workshop on Link Discovery, 2005, pp. 36–43.
- 2Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- 3HOG stands for the histogram of oriented gradients of an image
- 4B. Hall, A. Jaffe, and M. Trajtenberg, “The NBER Patent Citation Data File: Lessons, Insights and Methodological Tools,” National Bureau of Economic Research, Cambridge, MA, Tech. Rep. w8498,2001.